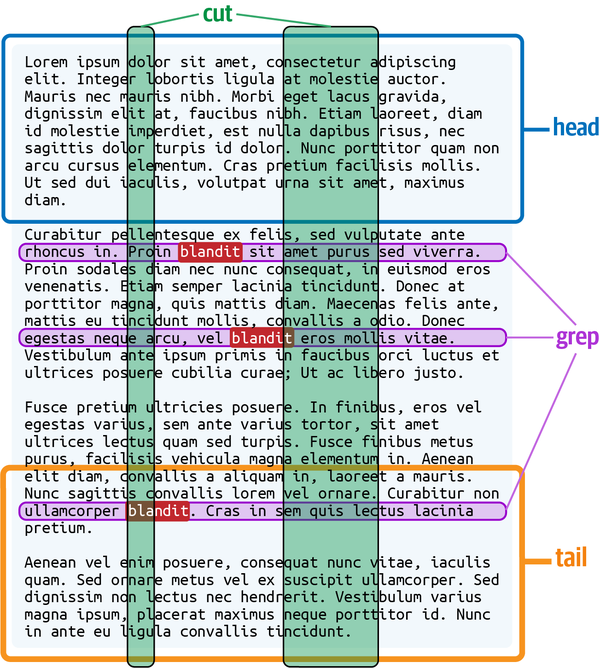
Producing Text
1
2
3
| $ cut -d: -f1 /etc/passwd | sort Print all usernames and sort them
$ cat *.txt | wc -l Total the number of lines
|
The date Command
1
2
3
4
5
6
7
8
9
| $ date Default formatting
Mon Jun 28 16:57:33 EDT 2021
$ date +%Y-%m-%d Year-Month-Day format
2021-06-28
$ date +%H:%M:%S Hour:Minute:Seconds format
16:57:33
$ date +"I cannot believe it's already %A!" Day of week
I cannot believe it's already Tuesday!
|
The seq Command
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| $ seq 1 5 Print all integers from 1 to 5, inclusive
1
2
3
4
5
$ seq 1 2 10 Increment by 2 instead of 1
1
3
5
7
9
$ seq 3 -1 0
3
2
1
0
$ seq 1.1 0.1 2 Increment by 0.1
1.1
1.2
1.3
⋮
2.0
$ seq -s/ 1 5 Separate values with forward slashes
1/2/3/4/5
# The option -w makes all values the same width (in characters) by adding leading zeros as needed:
$ seq -w 8 10
08
09
10
|
Brace Expansion (A Shell Feature)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| $ echo {1..10} Forward from 1
1 2 3 4 5 6 7 8 9 10
$ echo {10..1} Backward from 10
10 9 8 7 6 5 4 3 2 1
$ echo {01..10} With leading zeros (equal width)
01 02 03 04 05 06 07 08 09 10
$ echo {1..1000..100} Count by hundreds from 1
1 101 201 301 401 501 601 701 801 901
$ echo {1000..1..100} Backward from 1000
1000 900 800 700 600 500 400 300 200 100
$ echo {01..1000..100} With leading zeros
0001 0101 0201 0301 0401 0501 0601 0701 0801 0901
# Curly Braces Versus Square Brackets
$ ls
file1 file2 file4
$ ls file[2-4] Matches existing filenames
file2 file4
$ ls file{2..4} Evaluates to: file2 file3 file4
ls: cannot access 'file3': No such file or directory
file2 file4
$ echo {A..Z}
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
$ echo {A..Z} | tr -d ' ' Delete spaces
ABCDEFGHIJKLMNOPQRSTUVWXYZ
$ echo {A..Z} | tr ' ' '\n' Change spaces into newlines
A
B
C
⋮
Z
# Create an alias that prints the nth letter of the English alphabet:
$ alias nth="echo {A..Z} | tr -d ' ' | cut -c"
$ nth 10
J
|
The find Command
1
2
3
4
5
6
7
8
| $ find /etc -print List all of /etc recursively
/etc
/etc/issue.net
/etc/nanorc
/etc/apache2
/etc/apache2/sites-available
/etc/apache2/sites-available/default.conf
⋮
|
1
2
| $ find . -type f -print Files only
$ find . -type d -print Directories only
|
1
2
3
4
5
| $ find /etc -type f -name "*.conf" -print Files ending with .conf
/etc/logrotate.conf
/etc/systemd/logind.conf
/etc/systemd/timesyncd.conf
⋮
|
1
2
| # Make the name-matching case insensitive with the option -iname:
$ find . -iname "*.txt" -print
|
1
2
3
| # the following commands are equivalent
$ find . -iname "*.txt" -print
$ find -iname "*.txt"
|
1
2
3
4
5
| $ find /etc -exec echo @ {} @ ";"
@ /etc @
@ /etc/issue.net @
@ /etc/nanorc @
⋮
|
1
2
3
4
5
| $ find /etc -type f -name "*.conf" -exec ls -l {} ";"
-rw-r--r-- 1 root root 703 Aug 21 2017 /etc/logrotate.conf
-rw-r--r-- 1 root root 1022 Apr 20 2018 /etc/systemd/logind.conf
-rw-r--r-- 1 root root 604 Apr 20 2018 /etc/systemd/timesyncd.conf
⋮
|
1
2
3
4
5
| $ find $HOME/tmp -type f -name "*~" -exec echo rm {} ";" echo for safety
rm /home/smith/tmp/file1~
rm /home/smith/tmp/junk/file2~
rm /home/smith/tmp/vm/vm-8.2.0b/lisp/vm-cus-load.el~
$ find $HOME/tmp -type f -name "*~" -exec rm {} ";" Delete for real
|
1
2
| $ find /etc -type f -name "*.conf" -ls List .conf files like "ls -l"
$ find $HOME/tmp -type f -name "*~" -delete Delete tilde files
|
The yes Command
1
2
3
4
5
6
7
8
| $ yes Repeats "y" by default
y
y
y ^C Kill the command with Ctrl-C
$ yes woof! Repeat any other string
woof!
woof!
woof! ^C
|
1
2
3
4
| $ yes "Efficient Linux" | head -n3 Print a string 3 times
Efficient Linux
Efficient Linux
Efficient Linux
|
Isolating Text
grep: A Deeper Look
1
2
3
4
5
6
7
8
9
| $ cat frost
Whose woods these are I think I know.
His house is in the village though;
He will not see me stopping here
To watch his woods fill up with snow.
This is not the end of the poem.
$ grep his frost Print lines containing "his"
To watch his woods fill up with snow.
This is not the end of the poem. "This" matches "his"
|
1
2
3
| # Use the -w option to match whole words only:
$ grep -w his frost Match the word "his" exactly
To watch his woods fill up with snow.
|
1
2
3
4
5
6
7
8
9
| # Use the -i option to ignore the case of letters:
$ grep -i his frost
His house is in the village though; Matches "His"
To watch his woods fill up with snow. Matches "his"
This is not the end of the poem. "This" matches "his"
# Use the -l option to print only the names of the files that contain matching lines, but not the matching lines themselves:
$ grep -l his * Which files contain the string "his"?
frost
|
| To match this: | Use this syntax: | Example |
|---|
| Beginning of a line | ^ | ^a = Line beginning with a |
| End of a line | $ | !$ = Line ending with an exclamation point |
| Any single character (except newline) | . | … = Any three consecutive characters |
A literal caret, dollar sign, or any other special character c | \c | \$ = A literal dollar sign |
| Zero or more occurrences of expression E | E* | _* = Zero or more underscores |
| Any single character in a set | [characters] | [aeiouAEIOU] = Any vowel |
| Any single character not in a set | [^characters] | [^aeiouAEIOU] = Any nonvowel |
Any character in a given range between c1 and c2 | [c1-c2] | [0-9] = Any digit |
Any character not in a given range between c1 and c2 | [^c1-c2] | [^0-9] = Any nondigit |
Either of two expressions E1 or E2 | E1\\|E2 for grep and sed | one\\|two = Either one or two |
Either of two expressions E1 or E2 | E1\|E2 for awk | one\|two = Either one or two |
Grouping expression E for precedence | \(E\) for grep and sed | \(one\\|two\)* = Zero or more occurrences of one or two |
Grouping expression E for precedence | (E) for awk | (one\|two)* = Zero or more occurrences of one or two |
1
2
3
4
5
6
7
8
9
10
| # Match all lines that begin with a capital letter:
$ grep '^[A-Z]' myfile
# Match all nonblank lines (i.e., match blank lines and use -v to omit them):
$ grep -v '^$' myfile
# Match all lines that contain either cookie or cake:
$ grep 'cookie\|cake' myfile
# Match all lines at least five characters long:
$ grep '.....' myfile
# Match all lines in which a less-than symbol appears somewhere before a greater-than symbol, such as lines # of HTML code:
$ grep '<.*>' page.html
|
1
2
3
4
5
6
7
8
| $ grep w. frost
Whose woods these are I think I know.
He will not see me stopping here
To watch his woods fill up with snow.
$ grep 'w\.' frost
Whose woods these are I think I know.
To watch his woods fill up with snow.
|
1
2
3
4
5
6
| $ grep -F w. frost
Whose woods these are I think I know.
To watch his woods fill up with snow.
$ fgrep w. frost
Whose woods these are I think I know.
To watch his woods fill up with snow.
|
1
2
3
4
5
| # each line in /etc/passwd contains information about a user, organized as colon-separated fields. The final # field on each line is the program launched when the user logs in.
$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash 7th field is a shell
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin 7th field is not a shell
⋮
|
1
2
3
4
| $ cat /etc/shells
/bin/sh
/bin/bash
/bin/csh
|
1
2
3
4
| # Use the -f option (lowercase; don’t confuse it with -F) to match against a set of strings rather than a single string
$ cut -d: -f7 /etc/passwd | sort -u | grep -f /etc/shells -F
/bin/bash
/bin/sh
|
The tail Command
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # The tail command prints the last lines of a file—10 lines by default.
$ cat alphabet
A is for aardvark
B is for bunny
C is for chipmunk
⋮
X is for xenorhabdus
Y is for yak
Z is for zebu
$ tail -n3 alphabet
X is for xenorhabdus
Y is for yak
Z is for zebu
|
1
2
3
4
| # The following command begins at the 25th line of the file:
$ tail -n+25 alphabet
Y is for yak
Z is for zebu
|
1
2
3
| # To print the fourth line alone
$ head -n4 alphabet | tail -n1
D is for dingo
|
1
2
3
4
5
| # To print lines M through N, extract the first N lines with head, then isolate the last N-M+1 lines with tail. Print lines six through eight of the alphabet file:
$ head -n8 alphabet | tail -n3
F is for falcon
G is for gorilla
H is for hawk
|
The awk {print} Command
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| $ less /etc/hosts
127.0.0.1 localhost
127.0.1.1 myhost myhost.example.com
192.168.1.2 frodo
192.168.1.3 gollum
192.168.1.28 gandalf
# You need a command to print the second word on each line, which awk provides with ease:
$ awk '{print $2}' /etc/hosts
localhost
myhost
frodo
gollum
gandalf
# If the column number has more than one digit, surround the number with parentheses: for example, $(25). To refer to the final field, use $NF (“number of fields”). To refer to the entire line, use $0.
$ echo Efficient fun Linux | awk '{print $1 $3}' No whitespace
EfficientLinux
$ echo Efficient fun Linux | awk '{print $1, $3}' Whitespace
Efficient Linux
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| $ df / /data
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 1888543276 902295944 890244772 51% /
/dev/sda2 7441141620 1599844268 5466214400 23% /data
$ df / /data | awk '{print $4}'
Available
890244772
5466214400
$ df / /data | awk 'FNR>1 {print $4}'
890244772
5466214400
$ echo efficient:::::linux | awk -F':*' '{print $2}' Any number of colons
linux
|
Combining Text
1
2
3
4
5
6
7
8
9
10
11
12
| $ cat poem1
It is an ancient Mariner,
And he stoppeth one of three.
$ cat poem2
'By thy long grey beard and glittering eye,
$ cat poem3
Now wherefore stopp'st thou me?
$ cat poem1 poem2 poem3
It is an ancient Mariner,
And he stoppeth one of three.
'By thy long grey beard and glittering eye,
Now wherefore stopp'st thou me?
|
1
2
| $ echo efficient linux in $HOME
efficient linux in /home/smith
|
The tac Command
tac: A bottom-to-top combiner of text files
1
2
3
4
5
| $ cat poem1 poem2 poem3 | tac
Now wherefore stopp'st thou me?
'By thy long grey beard and glittering eye,
And he stoppeth one of three.
It is an ancient Mariner,
|
1
2
3
4
5
| $ tac poem1 poem2 poem3
And he stoppeth one of three. First file reversed
It is an ancient Mariner,
'By thy long grey beard and glittering eye, Second file
Now wherefore stopp'st thou me? Third file
|
tac is great for processing data that is already in chronological order but not reversible with the sort -r command.
A typical case is reversing a web-server log file to process its lines from newest to oldest:
1
2
3
| 192.168.1.34 - - [30/Nov/2021:23:37:39 -0500] "GET / HTTP/1.1" ...
192.168.1.10 - - [01/Dec/2021:00:02:11 -0500] "GET /notes.html HTTP/1.1" ...
192.168.1.8 - - [01/Dec/2021:00:04:30 -0500] "GET /stuff.html HTTP/1.1" ...
|
The paste Command
paste: A side-by-side combiner of text files
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| $ cat title-words1
EFFICIENT
AT
COMMAND
$ cat title-words2
linux
the
line
$ paste title-words1 title-words2
EFFICIENT linux
AT the
COMMAND line
$ paste title-words1 title-words2 | cut -f2 cut & paste are complementary
linux
the
line
|
1
2
3
4
| $ paste -d, title-words1 title-words2
EFFICIENT,linux
AT,the
COMMAND,line
|
1
2
3
| $ paste -d, -s title-words1 title-words2
EFFICIENT,AT,COMMAND
linux,the,line
|
1
2
3
4
5
6
7
| $ paste -d "\n" title-words1 title-words2
EFFICIENT
linux
AT
the
COMMAND
line
|
The diff Command
diff: A command that interleaves text from two files by printing their differences
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| $ cat file1
Linux is all about efficiency.
I hope you will enjoy this book.
$ cat file2
MacOS is all about efficiency.
I hope you will enjoy this book.
Have a nice day.
$ diff file1 file2
# line 1 in the first file differs from line 1 in the second file
1c1
< Linux is all about efficiency.
---
> MacOS is all about efficiency.
# file2 has a third line not present after the second line of file1
2a3
> Have a nice day.
|
1
2
3
4
5
6
7
8
9
| # isolate the differing lines with grep and cut
$ diff file1 file2 | grep '^[<>]'
< Linux is all about efficiency.
> MacOS is all about efficiency.
> Have a nice day.
$ diff file1 file2 | grep '^[<>]' | cut -c3-
Linux is all about efficiency.
MacOS is all about efficiency.
Have a nice day.
|
Transforming Text
The tr Command
Translates characters into other characters
1
2
3
4
5
6
7
| $ echo $PATH | tr : "\n" Translate colons into newlines
/home/smith/bin
/usr/local/bin
/usr/bin
/bin
/usr/games
/usr/lib/java/bin
|
1
2
3
4
| $ echo efficient | tr a-z A-Z Translate a into A, b into B, etc
EFFICIENT
$ echo Efficient | tr A-Z a-z
efficient
|
1
2
3
| $ echo Efficient Linux | tr " " "\n"
Efficient
Linux
|
1
2
| $ echo efficient linux | tr -d ' \t' Remove spaces and tabs
efficientlinux
|
The rev Command
Reverses characters on a line
1
2
| $ echo Efficient Linux! | rev
!xuniL tneiciffE
|
1
2
3
4
5
| $ cat celebrities
Jamie Lee Curtis
Zooey Deschanel
Zendaya Maree Stoermer Coleman
Rihanna
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| # extract the final word on each line
$ rev celebrities
sitruC eeL eimaJ
lenahcseD yeooZ
nameloC remreotS eeraM ayadneZ
annahiR
$ rev celebrities | cut -d' ' -f1
sitruC
lenahcseD
nameloC
annahiR
$ rev celebrities | cut -d' ' -f1 | rev
Curtis
Deschanel
Coleman
Rihanna
|
The awk and sed Commands
General-purpose transformers
1
2
| $ sed 10q myfile Print 10 lines and quit (q)
$ awk 'FNR<=10' myfile Print while line number is ≤ 10
|
1
2
3
4
| $ echo image.jpg | sed 's/\.jpg/.png/' Replace .jpg by .png
image.png
$ echo "linux efficient" | awk '{print $2, $1}' Swap two words
efficient linux
|
I highly recommend spending quality time learning both commands (or at least one of them).
awk essentials
awk transforms lines of text from files (or stdin) into any other text, using a sequence of instructions called an awk program.
1
| $ awk program input-files
|
1
| $ awk -f program-file1 -f program-file2 -f program-file3 input-files
|
Each instruction in the program has the form:
1
2
3
4
5
6
7
8
9
| Typical patterns include:
* The word `BEGIN`
Its action runs just once, before `awk` processes any input.
* The word `END`
Its action runs just once, after `awk` has processed all the input.
* regular expression (see Table 5-1) surrounded by forward slashes
An example is `/^[A-Z]/` to match lines that begin with a capital letter.
* other expressions specific to `awk`
For example, to check whether the third field on an input line ($3) begins with a capital letter, a pattern would be $3~/^[A-Z]/. Another example is FNR>5, which tells awk to skip the first five lines of input.
|
1
2
3
4
5
6
| # print the celebrity’s last name
$ awk '{print $NF}' celebrities
Curtis
Deschanel
Coleman
Rihanna
|
1
2
| $ echo efficient linux | awk '/efficient/'
efficient linux
|
1
2
3
4
5
6
7
8
| $ awk -F'\t' '{print $4, "(" $3 ").", "\"" $2 "\""}' animals.txt
Lutz, Mark (2010). "Programming Python"
Barrett, Daniel (2005). "SSH, The Secure Shell"
Schwartz, Randal (2012). "Intermediate Perl"
Bell, Charles (2014). "MySQL High Availability"
Siever, Ellen (2009). "Linux in a Nutshell"
Boney, James (2005). "Cisco IOS in a Nutshell"
Roman, Steven (1999). "Writing Word Macros"
|
1
2
| $ awk -F'\t' '/^horse/{print $4, "(" $3 ").", "\"" $2 "\""}' animals.txt
Siever, Ellen (2009). "Linux in a Nutshell"
|
1
2
3
4
| $ awk -F'\t' '$3~/^201/{print $4, "(" $3 ").", "\"" $2 "\""}' animals.txt
Lutz, Mark (2010). "Programming Python"
Schwartz, Randal (2012). "Intermediate Perl"
Bell, Charles (2014). "MySQL High Availability"
|
1
2
3
4
5
6
7
8
9
10
| $ awk -F'\t' \
'BEGIN {print "Recent books:"} \
$3~/^201/{print "-", $4, "(" $3 ").", "\"" $2 "\""} \
END {print "For more books, search the web"}' \
animals.txt
Recent books:
- Lutz, Mark (2010). "Programming Python"
- Schwartz, Randal (2012). "Intermediate Perl"
- Bell, Charles (2014). "MySQL High Availability"
For more books, search the web
|
1
2
| $ seq 1 100 | awk '{s+=$1} END {print s}'
5050
|
Resource:
Improving the duplicate file detector
1
2
3
4
| $ md5sum *.jpg | cut -c1-32 | sort | uniq -c | sort -nr | grep -v " 1 "
3 f6464ed766daca87ba407aede21c8fcc
2 c7978522c58425f6af3f095ef1de1cd5
2 146b163929b6533f02e91bdf21cb9563
|
1
2
3
4
5
| $ md5sum *.jpg
146b163929b6533f02e91bdf21cb9563 image001.jpg
63da88b3ddde0843c94269638dfa6958 image002.jpg
146b163929b6533f02e91bdf21cb9563 image003.jpg
⋮
|
1
| $ md5sum *.jpg | awk '{counts[$1]++}'
|
1
2
3
4
5
6
7
| $ md5sum *.jpg \
| awk '{counts[$1]++} \
END {for (key in counts) print counts[key]}'
1
2
2
⋮
|
1
2
3
4
5
6
7
| $ md5sum *.jpg \
| awk '{counts[$1]++} \
END {for (key in counts) print counts[key] " " key}'
1 714eceeb06b43c03fe20eb96474f69b8
2 146b163929b6533f02e91bdf21cb9563
2 c7978522c58425f6af3f095ef1de1cd5
⋮
|
1
2
3
4
5
6
7
| $ md5sum *.jpg \
| awk '{counts[$1]++; names[$1]=names[$1] " " $2} \
END {for (key in counts) print counts[key] " " key ":" names[key]}'
1 714eceeb06b43c03fe20eb96474f69b8: image011.jpg
2 146b163929b6533f02e91bdf21cb9563: image001.jpg image003.jpg
2 c7978522c58425f6af3f095ef1de1cd5: image019.jpg image020.jpg
⋮
|
1
2
3
4
5
6
7
8
| $ md5sum *.jpg \
| awk '{counts[$1]++; names[$1]=names[$1] " " $2} \
END {for (key in counts) print counts[key] " " key ":" names[key]}' \
| grep -v '^1 ' \
| sort -nr
3 f6464ed766daca87ba407aede21c8fcc: image007.jpg image012.jpg image014.jpg
2 c7978522c58425f6af3f095ef1de1cd5: image019.jpg image020.jpg
2 146b163929b6533f02e91bdf21cb9563: image001.jpg image003.jpg
|
sed essentials
1
| $ sed script input-files
|
1
| $ sed -e script1 -e script2 -e script3 input-files
|
1
| $ sed -f script-file1 -f script-file2 -f script-file3 input-files
|
1
2
| $ echo Efficient Windows | sed "s/Windows/Linux/"
Efficient Linux
|
1
2
3
4
5
| $ sed 's/.* //' celebrities
Curtis
Deschanel
Coleman
Rihanna
|
s/one/two/ = s_one_two_ = s@one@two@
1
2
3
4
| $ echo Efficient Stuff | sed "s/stuff/linux/" Case sensitive; no match
Efficient Stuff
$ echo Efficient Stuff | sed "s/stuff/linux/i" Case-insensitive match
Efficient linux
|
1
2
3
4
| $ echo efficient stuff | sed "s/f/F/" Replaces just the first "f"
eFficient stuff
$ echo efficient stuff | sed "s/f/F/g" Replaces all occurrences of "f"
eFFicient stuFF
|
1
2
3
4
5
| $ seq 10 14 | sed 4d Remove the 4th line
10
11
12
14
|
1
2
3
4
5
6
| $ seq 101 200 | sed '/[13579]$/d' Delete lines ending in an odd digit
102
104
106
⋮
200
|
Matching subexpressions with sed
1
2
| $ ls
image.jpg.1 image.jpg.2 image.jpg.3
|
1
2
3
4
| $ ls | sed "s/image\.jpg\.\([1-3]\)/image\1.jpg/"
image1.jpg
image2.jpg
image3.jpg
|
1
2
| $ ls
apple.jpg.1 banana.png.2 carrot.jpg.3
|
1
2
3
4
| $ ls | sed "s/\([a-z][a-z]*\)\.\([a-z][a-z][a-z]\)\.\([0-9]\)/\1\3.\2/"
apple1.jpg
banana2.png
carrot3.jpg
|
resources:
1
2
3
4
5
| $ cat title.txt
This book is titled "Efficient Linux at the Command Line"
$ fold -w40 title.txt
This book is titled "Efficient Linux at
the Command Line"
|
1
2
3
4
5
| $ man -k width
DisplayWidth (3) - image format functions and macros
DisplayWidthMM (3) - image format functions and macros
fold (1) - wrap each input line to fit in specified width
⋮
|
A great starting point for asking effective questions is Stack Overflow’s “How Do I Ask a Good Question?” help page how-to-ask.
The name grep is short for “get regular expression and print.” The name awk is an acronym for Aho, Weinberger, and Kernighan, the program’s creators. The name sed is short for “stream editor,” because it edits a stream of text.